DroongaとGroongaのベンチマークの取り方
チュートリアルのゴール
Droongaクラスタのベンチマークを測定し、Groongaでの結果と比較するまでの、一連の手順を学ぶこと。
前提条件
- UbuntuまたはCentOSのサーバの操作に関する基本的な知識と経験があること。
- GroongaをHTTP経由で操作する際の基本的な知識と経験があること。
- Droongaクラスタの構築手順について基本的な知識があること。 このチュートリアルの前に、「使ってみる」のチュートリアルを完了しておいて下さい。
ベンチマークの必要性について
DroongaはGroongaと互換性があるため、GroongaベースのアプリケーションをDroongaに移行することを検討することもあるでしょう。 そんな時は、実際に移行する前に、Droongaの性能を測定して、より良い移行先であるかどうかを確認しておくべきです。
もちろん、単にGroongaとDroongaの性能差を知りたいと思うこともあるでしょう。 ベンチマークによって、差を可視化することができます。
性能の可視化の方法
あるシステムの性能を表す指標としては、以下の2つが多く使われます。
- レイテンシー
- スループット
レイテンシーとは、システムがリクエストを受け取ってからレスポンスを返すまでに実際にかかった応答時間のことです。 言い換えると、これは各リクエストについてクライアントが待たされた時間です。 この指標においては、数値は小さければ小さいほどよいです。 一般的に、クエリが軽い場合や、データベースのサイズが小さい場合、クライアント数が少ない場合に、レイテンシーは小さくなります。
スループットは、一度にどれだけの数のリクエストを捌けるかを意味するものです。 性能の指標は「クエリ毎秒(Queries Per Second, qps)」という単位で表されます。 例えば、あるGroongaサーバが1秒に10件のリクエストを処理できたとき、これを「10qps」と表現します。 10人のユーザ(クライアント)がいるのかもしれませんし、2人のユーザがそれぞれブラウザ上で5つのタブを開いているのかもしれません。 ともかく、「10qps」という数値は、1秒が経過する間にそのGroongaサーバが実際に10件のリクエストを受け付けて、レスポンスを返したということを意味します。
ベンチマークは、drnbenchというGemパッケージによって導入されるdrnbench-request-responseコマンドで行うことができます。
このツールは、計測対象のサービスについてレイテンシーとスループットの両方を計測できます。
ベンチマークツールはどのように性能を測定するのか
drnbench-request-responseは、対象サービスの性能を以下のようにして計測します:
- マスタープロセスが仮想クライアントを1つ生成する。 このクライアントは即座に動き始め、対象サービスに対して多数のリクエストを連続して頻繁に送り続ける。
- しばらくしたら、マスタープロセスがクライアントを終了させる。 そして、応答のデータから最小・最大・平均の経過時間を計算する。 また、実際に対象サービスによって処理されたリクエストの件数を集計し、結果を1クライアントの場合のqps値として報告する。
- マスタープロセスが仮想クライアントを2つ生成する。 これらのクライアントはリクエストを送り始める。
- しばらくしたら、マスタープロセスがすべてのクライアントを終了させる。 そして、最小・最大・平均の経過時間を計算すると同時に、実際に対象サービスに処理されたリクエストの件数を集計し、結果を2クライアントの場合のqps値として報告する。
- 3クライアントの場合、4クライアントの場合……と、クライアント数を増やしながら繰り返す。
-
最後に、マスタープロセスが最小・最大・平均の経過時間、qps値、およびその他の情報をまとめたものを、以下のようなCSVファイルとして保存する:
n_clients,total_n_requests,queries_per_second,min_elapsed_time,max_elapsed_time,average_elapsed_time,200 1,996,33.2,0.001773766,0.238031643,0.019765581680722916,100.0 2,1973,65.76666666666667,0.001558398,0.272225481,0.020047345673086702,100.0 4,3559,118.63333333333334,0.001531184,0.39942581,0.023357554419499882,100.0 6,4540,151.33333333333334,0.001540704,0.501663069,0.042344890696916264,100.0 8,4247,141.56666666666666,0.001483995,0.577100609,0.045836844514480835,100.0 10,4466,148.86666666666667,0.001987089,0.604507078,0.06949704923846833,100.0 12,4500,150.0,0.001782343,0.612596799,0.06902839555222215,100.0 14,4183,139.43333333333334,0.001980711,0.60754769,0.1033681068718623,100.0 16,4519,150.63333333333333,0.00284654,0.653204575,0.09473386513387955,100.0 18,4362,145.4,0.002330049,0.640683693,0.12581190483929405,100.0 20,4228,140.93333333333334,0.003710795,0.662666076,0.1301649290901133,100.0この結果は、分析や、グラフ描画など、様々な使い方ができます。
(注意: 性能測定の結果は様々な要因によって変動します。 これはあくまで特定のバージョン、特定の環境での結果の例です。)
結果の読み方と分析の仕方
上の例を見て下さい。
HTTPレスポンスのステータス
最後の列、200を見て下さい。
これはHTTPレスポンスのステータスの割合を示しています。
200は「OK」、0は「タイムアウト」です。
400や500などのエラーレスポンスが得られた場合も、同様に報告されます。
これらの情報は、意図しない速度低下の原因究明に役立つでしょう。
レイテンシー
レイテンシーは簡単に分析できます。値が小さければ小さいほどよいと言えます。 対象サービスのキャッシュ機構が正常に動作している場合、最小と平均の応答時間は小さくなります。 最大応答時間は、重たいクエリ、システムのメモリのスワップの発生、意図しないエラーの発生などの影響を受けます。
レイテンシーのグラフは、有用な同時接続数の上限も明らかにします。
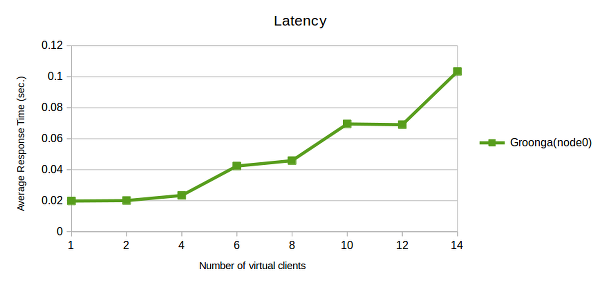
これはaverage_elapsed_timeのグラフです。
4クライアントを越えた所で経過時間が増加していることが見て取れるでしょう。
これは何を意味するのでしょうか?
Groongaは利用可能なプロセッサ数と同じ数だけのリクエストを完全に並行処理できます。 コンピュータのプロセッサ数が4である場合、そのシステムは4件以下のリクエストについては余計な待ち時間無しで同時に処理することができます。 それ以上の数のリクエストが来た場合、5番目以降のリクエストは、それ以前に受け付けたリクエストの処理完了後に処理されます。 先のグラフは、この理論上の上限が事実であることを示しています。
スループット
スループット性能の分析にも、グラフが便利です。
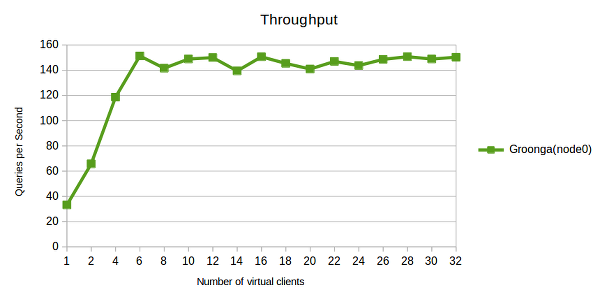
6クライアントを超えたあたりで、qps値が150前後で頭打ちになっているのを見て取れるでしょう。 これは、計測対象のサービスが1秒あたり最大で150件のリクエストを処理できるということを意味しています。
言い直すと、この結果は「(ハードウェア、ソフトウェア、ネットワーク、データベースの大きさ、クエリの内容など、様々な要素をひっくるめた)このシステムのスループットの性能限界は150qpsである」という風に読み取ることができます。 もしサービスに対するリクエストの件数が増加しつつあり、この限界に近づいているようであれば、クエリの最適化やコンピュータ自体のアップグレードなど、何らかの対策を取ることを検討する必要があると言えます。
性能の比較
同じリクエストのパターンをGroongaとDroongaに送ることで、各システムの性能を比較することができます。 もしDroongaの方が性能が良ければ、サービスのバックエンドをGroongaからDroongaに移行する根拠になり得ます。
また、異なるノード数での結果を比較すると、新しくノードを追加する際のコストパフォーマンスを分析することもできます。
ベンチマーク環境を用意する
新しいDroongaクラスタのために、以下の、互いにホスト名で名前解決できる4つのUbuntu 15.10のサーバがあると仮定します:
192.168.100.50、ホスト名:node0192.168.100.51、ホスト名:node1192.168.100.52、ホスト名:node2192.168.100.53、ホスト名:node3
1つはクライアント用で、残りの3つはDroongaノード用です。
比較対照のデータベース(およびそのデータソース)を用意する
もしすでにGroongaベースのサービスを運用しているのであれば、それ自体が比較対照となります。 この場合、Groongaデータベースの内容すべてをダンプ出力し、新しく用意したDroongaクラスタに流し込みさえすれば、性能比較を行えます。
特に運用中のサービスが無いということであれば、有効なベンチマークを取るために大量のデータを格納したデータベースを、対照として用意する必要があります。 wikipedia-searchリポジトリには、Wikipedia日本語版のページを格納したGroongaサーバ(およびDroongaクラスタ)を用意する手助けとなるスクリプトが含まれています。
では、Wikipediaのページを格納したGroongaデータベースを、node0のノードに準備しましょう。
-
データベースのサイズを決める。 ベンチマーク測定のためには、十分に大きいサイズのデータベースを使う必要があります。
- もしデータベースが小さすぎれば、Droongaのオーバーヘッドが相対的に大きくなるため、Droongaにとって過度に悲観的なベンチマーク結果となるでしょう。
- もしデータベースが大きすぎれば、メモリのスワップが発生してシステムの性能がランダムに劣化するために、過度に不安定なベンチマーク結果となるでしょう。
- 各ノードのメモリの搭載量が異なる場合、その中で最もメモリ搭載量が少ないノードに合わせてデータベースのサイズを決めるのが望ましいです。
例えば、
node0(8GB RAM),node1(8GB RAM),node2(6GB RAM)の3つのノードがあるとすれば、データベースは6GBよりも小さくするべきです。 -
インストール手順に従ってGroongaサーバをセットアップする。
(on node0) % sudo apt-get -y install software-properties-common % sudo add-apt-repository -y universe % sudo add-apt-repository -y ppa:groonga/ppa % sudo apt-get update % sudo apt-get -y install groongaこれでGroongaを利用できるようになります。.
-
Rakeのタスク
data:convert:groonga:jaを使って、Wikipediaのページのアーカイブをダウンロードし、Groongaのダンプファイルに変換する。 変換するレコード(ページ)の数は、環境変数MAX_N_RECORDS(初期値は5000)で指定することができます。(on node0) % cd ~/ % git clone https://github.com/droonga/wikipedia-search.git % cd wikipedia-search % bundle install --path vendor/ % time (MAX_N_RECORDS=1500000 bundle exec rake data:convert:groonga:ja \ data/groonga/ja-pages.grn)アーカイブは非常に大きいため、ダウンロードと変換には時間がかかります。
変換が終わったら、
~/wikipedia-search/data/groonga/ja-pages.grnの位置にダンプファイルが生成されています。 新しいデータベースを作成し、ダンプファイルの内容を流し込みましょう。 この操作にも時間がかかります:(on node0) % mkdir -p $HOME/groonga/db/ % groonga -n $HOME/groonga/db/db quit % time (cat ~/wikipedia-search/config/groonga/schema.grn | groonga $HOME/groonga/db/db) % time (cat ~/wikipedia-search/config/groonga/indexes.grn | groonga $HOME/groonga/db/db) % time (cat ~/wikipedia-search/data/groonga/ja-pages.grn | groonga $HOME/groonga/db/db)注意: レコードの数がデータベースのサイズに影響します。 参考までに、検証環境での結果を以下に示します:
- 30万件のレコードから、1.1GBのデータベースができました。 データの変換には17分、流し込みには6分を要しました。
- 150万件のレコードから、4.3GBのデータベースができました。 データの変換には53分、流し込みには64分を要しました。
-
GroongaをHTTPサーバとして起動する
(on node0) % groonga -p 10041 -d --protocol http $HOME/groonga/db/db
これで、このノードをベンチマーク測定の対照として使う準備が整いました。
Droongaクラスタをセットアップする
Droongaをすべてのノードにインストールします。
HTTP経由での動作をベンチマーク測定するので、droonga-engineとdroonga-http-serverの両方をインストールする必要があります。
(on node0)
% host=node0
% curl https://raw.githubusercontent.com/droonga/droonga-engine/master/install.sh | \
sudo HOST=$host bash
% curl https://raw.githubusercontent.com/droonga/droonga-http-server/master/install.sh | \
sudo ENGINE_HOST=$host HOST=$host PORT=10042 bash
% sudo droonga-engine-catalog-generate \
--hosts=node0,node1,node2
% sudo service droonga-engine start
% sudo service droonga-http-server start
(on node1)
% host=node1
...
(on node2)
% host=node2
...
注意: droonga-http-serverをGroongaとは別のポート番号で起動するために、ここではPORT環境変数を使って上記のようにして10042のポートで起動するように指定しています。
DroongaのHTTPサーバが動作しており、10042番のポートを監視していることと、3つのノードからなるクラスタとして動作していることを確認しておきましょう:
(on node0)
% curl "http://node0:10042/droonga/system/status"
{
"nodes": {
"node0:10031/droonga": {
"live": true
},
"node1:10031/droonga": {
"live": true
},
"node2:10031/droonga": {
"live": true
}
}
}
GroongaからDroongaへとデータを同期する
次に、Droongaのデータベースを用意します。
grn2drnコマンドを使うと、Groongaのダンプ出力をDroonga用のメッセージに変換することができます。
コマンドを利用できるようにするために、Groongaサーバとなっているコンピュータにgrn2drn Gemパッケージをインストールしましょう。
(on node0)
% sudo gem install grn2drn
また、rroonga Gemパッケージの一部として導入されるgrndumpコマンドは、既存のGroongaのデータベースからすべてのデータを柔軟に取り出す機能を提供しています。
もし既存のGroongaサーバからデータを取り出そうとしているのであれば、事前にrroongaをインストールしておく必要があります。
(on Ubuntu server)
% sudo apt-get -y install software-properties-common
% sudo add-apt-repository -y universe
% sudo add-apt-repository -y ppa:groonga/ppa
% sudo apt-get update
% sudo apt-get -y install libgroonga-dev
% sudo gem install rroonga
(on CentOS server)
# rpm -ivh http://packages.groonga.org/centos/groonga-release-1.1.0-1.noarch.rpm
# yum -y makecache
# yum -y ruby-devel groonga-devel
# gem install rroonga
それでは、スキーマ定義とデータを別々にダンプ出力し、Droongaクラスタに流し込みましょう。
(on node0)
% time (grndump --no-dump-tables $HOME/groonga/db/db | \
grn2drn | \
droonga-send --server=node0 \
--report-throughput)
% time (grndump --no-dump-schema --no-dump-indexes $HOME/groonga/db/db | \
grn2drn | \
droonga-send --server=node0 \
--server=node1 \
--server=node2 \
--messages-per-second=100 \
--report-throughput)
スキーマ定義とインデックスの定義については単一のエンドポイントに送るように注意して下さい。 Droongaは複数のノードに並行してバラバラに送られたスキーマ変更コマンドをソートすることができないので、スキーマ定義のリクエストを複数のエンドポイントに流し込むと、データベースが壊れてしまいます。
トラフィックとシステムの負荷を軽減するために、1秒あたりに流入するメッセージの量を--messages-per-secondオプションで制限するようにしてください。
大量のメッセージが一度にDroongaクラスタに流れ込むと、システムの限界を超えてしまい、Droongaがメモリを食い潰して、システムを非常に低速にしてしまう恐れがあります。
この操作にも時間がかかります。
例えば --messages-per-second=100 と指定した場合、150万件のレコードを同期するにはだいたい4時間ほどかかります。(必要な時間は 150000 / 100 / 60 / 60 のような計算式で見積もれます)
以上の手順により、10041ポートを監視するGroonga HTTPサーバと、10042ポートを監視するDroonga HTTPサーバの、2つのHTTPサーバを用意できます。
クライアントをセットアップする
クライアントにするマシンには、ベンチマーク用のクライアントをインストールする必要があります。
node3をクライアントとして使うと仮定します:
(on node3)
% sudo apt-get update
% sudo apt-get -y upgrade
% sudo apt-get install -y ruby curl
% sudo gem install drnbench
リクエストパターンを用意する
ベンチマーク用のリクエストパターンファイルを用意しましょう。
キャッシュヒット率を決める
まず、キャッシュヒット率を決める必要があります。
もし既に運用中のGroongaベースのサービスがあるのであれば、以下のようにして、statusコマンドを使ってGroongaデータベースのキャッシュヒット率を調べることができます:
% curl "http://node0:10041/d/status"
[
[
0,
1412326645.19701,
3.76701354980469e-05
],
{
"max_command_version": 2,
"alloc_count": 158,
"starttime": 1412326485,
"uptime": 160,
"version": "4.0.6",
"n_queries": 1000,
"cache_hit_rate": 0.5,
"command_version": 1,
"default_command_version": 1
}
]
キャッシュヒット率は"cache_hit_rate"として返却されます。
0.5は50%という意味で、レスポンスのうちの半分がキャッシュされた結果に基づいて返されているということです。
運用中のサービスが無いのであれば、ひとまずキャッシュヒット率は50%と過程すると良いでしょう。
GroongaとDroongaの性能を正確に比較するためには、キャッシュヒット率が実際の値に近くなるようにリクエストパターンを用意する必要があります。 さて、どのようにすればよいのでしょうか?
キャッシュヒット率は、N = 100 ÷ (キャッシュヒット率)という式で計算した、ユニーク(一意)なリクエストパターンの数で制御できます。
これは、GroongaとDroonga(droonga-http-server)が既定の状態で最大で100件までの結果をキャッシュするためです。
期待されるキャッシュヒット率が50%なのであれば、用意するべきユニークなリクエストの数はN = 100 ÷ 0.5 = 200と計算できます。
注意: 実際のキャッシュヒット率が0に近い場合、必要となるユニークなリクエストの件数が巨大になってしまいます。
このような場合は、キャッシュヒット率を0.01(1%)程度と見なすとよいでしょう。
リクエストパターンファイルの書式
drnbench-request-response用のリクエストパターンのリストは、HTTPリクエストのパスのリストであるプレーンテキスト形式で作成します。
以下はGroongaのselectコマンド用のリクエストの一覧の例です:
/d/select?command_version=2&table=Pages&limit=10&match_columns=title&output_columns=title&query=AAA
/d/select?command_version=2&table=Pages&limit=10&match_columns=title&output_columns=title&query=BBB
...
もし既存のGroongaベースのサービスを運用しているのであれば、リクエストパターンのリストは、実際のアクセスログやクエリログなどから生成するのが望ましいです。 実際のリクエストに近いパターンであるほど、システムの性能をより有効に測定できます。 ユニークなリクエストパターンを200件作るには、ログからユニークなリクエスト先パスを200件収集してくればOKです。
運用中のサービスが無い場合は、何らかの方法でリクエストパスのリストを作る必要があります。 詳しくは事項を参照して下さい。
検索語句のリストを用意する
200件のユニークなリクエストパターンを作るには、200個の語句を用意する必要があります。
しかも、それらはすべて実際にGroongaのデータベースで有効な検索結果を返すものでなくてはなりません。
もしランダムに生成した単語(例えばP2qyNJ9L, Hy4pLKc5, D5eftuTp……といった具合)を使った場合、ほとんどのリクエストに対して「ヒット無し」という検索結果が返されてしまうため、有効なベンチマーク結果を得ることができません。
こんな時のために、drnbench-extract-searchtermsというユーティリティコマンドがあります。
これは、以下のようにしてGroongaの検索結果から単語のリストを生成します:
% curl "http://node0:10041/d/select?command_version=2&table=Pages&limit=10&output_columns=title" | \
drnbench-extract-searchterms
title1
title2
title3
...
title10
drnbench-extract-searchtermsは検索結果のレコードの最初の列の値を単語として取り出します。
200件の有効な検索語句を得るには、単にlimit=200と指定して検索結果を得ればOKです。
与えられた語句からリクエストパターンファイルを生成する
では、drnbench-extract-searchtermsを使って、Groongaの検索結果からリクエストパターンを生成してみましょう。
% n_unique_requests=200
% curl "http://node0:10041/d/select?command_version=2&table=Pages&limit=$n_unique_requests&output_columns=title" | \
drnbench-extract-searchterms --escape | \
sed -r -e "s;^;/d/select?command_version=2\&table=Pages\&limit=10\&match_columns=title,text\&output_columns=snippet_html(title),snippet_html(text),categories,_key\&query_flags=NONE\&sortby=title\&drilldown=categories\&drilldown_limit=10\&drilldown_output_columns=_id,_key,_nsubrecs\&drilldown_sortby=_nsubrecs\&query=;" \
> ./patterns.txt
注意:
- sedスクリプトの中の
&は、前にバックスラッシュを置いて\&のようにエスケープする必要があることに注意して下さい。 drnbench-extract-searchtermsコマンドには、--escapeオプションを指定すると良いでしょう。 この指定により、URIに含められない文字がエスケープされます。- 得られた検索語句を
queryパラメータに使用する場合、query_flags=NONEも同時に指定すると良いでしょう。 この指定により、Groongaはqueryパラメータの中に含まれる特殊文字を無視するようになります。 この指定を忘れると、不正なクエリのエラーに遭遇することになるかもしれません。
生成されたファイル patterns.txt は以下のような内容になります:
/d/select?command_version=2&table=Pages&limit=10&match_columns=title,text&output_columns=snippet_html(title),snippet_html(text),categories,_key&query_flags=NONE&sortby=title&drilldown=categories&drilldown_limit=10&drilldown_output_columns=_id,_key,_nsubrecs&drilldown_sortby=_nsubrecs&query=AAA
/d/select?command_version=2&table=Pages&limit=10&match_columns=title,text&output_columns=snippet_html(title),snippet_html(text),categories,_key&query_flags=NONE&sortby=title&drilldown=categories&drilldown_limit=10&drilldown_output_columns=_id,_key,_nsubrecs&drilldown_sortby=_nsubrecs&query=BBB
...
ベンチマークを実行する
以上で、準備が整いました。 それではGroongaとDroongaのベンチマークを取得してみましょう。
Groongaのベンチマークを行う
まず、比較対照としてGroongaでのベンチマーク結果を取得します。
node0を比較対照用のGroongaサーバとしてセットアップ済みで、GroongaのHTTPサーバが停止している場合には、ベンチマークの実行前にあらかじめ起動しておいて下さい。
(on node0)
% groonga -p 10041 -d --protocol http $HOME/groonga/db/db
ベンチマークは以下の要領で、drnbench-request-responseコマンドを実行すると測定できます:
(on node3)
% drnbench-request-response \
--step=2 \
--start-n-clients=0 \
--end-n-clients=20 \
--duration=30 \
--interval=10 \
--request-patterns-file=$PWD/patterns.txt \
--default-hosts=node0 \
--default-port=10041 \
--output-path=$PWD/groonga-result.csv
重要なパラメータは以下の通りです:
--stepは、各段階で増やす仮想クライアントの数です。--start-n-clientsは、仮想クライアントの最初の数です。 例え0を指定したとしても、最初の実行時には必ず1つはクライアントが生成されます。--end-n-clientsは、仮想クライアントの最大数です。 ベンチマークは、クライアントの数がこの上限に達するまでの間繰り返し実行されます。--durationは、1回あたりのベンチマークの実行にかける時間です。 この値は、結果が安定するまでに十分な長さの時間を指定するのが望ましいです。 筆者の場合は30(秒)が最適でした。--intervalは、ベンチマークの合間に設ける待ち時間です。 これは、前回のベンチマークが終了するのに十分な長さの時間を指定するのが望ましいです。 筆者の場合は10(秒)が最適でした。--request-patterns-fileは、パターンファイルへのパスです。--default-hostsは、リクエストの送信先のホスト名の一覧です。 複数のホストをカンマで区切って指定すると、ロードバランサーの動作をシミュレートすることもできます。--default-portは、リクエストの送信先のポート番号です。--output-pathは、結果の出力先ファイルへのパスです。 すべてのベンチマークの統計情報が、この位置にファイルとして保存されます。
ベンチマークの実行中は、node0のシステムの状態をtopコマンドなどを使って監視しておきましょう。
もしベンチマークがGroongaの性能を正しく引き出していれば、GroongaのプロセスはCPUをフルに使い切っているはずです(プロセッサ数4ならば400%、といった具合に)。
そうでない場合は、何かがおかしいです。例えばネットワーク帯域が細すぎるのかもしれませんし、クライアントが非力すぎるのかもしれません。
これで、対照用のGroongaでの結果を得る事ができます。
結果が妥当かどうかを確かめるために、statusコマンドの結果を確認しましょう:
% curl "http://node0:10041/d/status"
[
[
0,
1412326645.19701,
3.76701354980469e-05
],
{
"max_command_version": 2,
"alloc_count": 158,
"starttime": 1412326485,
"uptime": 160,
"version": "4.0.6",
"n_queries": 1000,
"cache_hit_rate": 0.49,
"command_version": 1,
"default_command_version": 1
}
]
"cache_hit_rate"の値に注目してください。
この値が想定されるキャッシュ率(例えば0.5)からかけ離れている場合、何かがおかしいです。例えば、リクエストパターンの数が少なすぎるかも知れません。
キャッシュヒット率が高すぎる場合、結果のスループットは本来よりも高すぎる値になってしまいます。
Droongaノードの上でGroongaを動かしている場合は、CPU資源とメモリ資源を解放するために、ベンチマーク取得後はGroongaを停止しておきましょう。
(on node0)
% pkill groonga
Droongaのベンチマークを行う
1ノード構成でのDroongaのベンチマーク
ベンチマークの前に、ノードが1つだけの状態にクラスタを設定します。
(on node1, node2)
% sudo systemctl stop droonga-engine
% sudo systemctl stop droonga-http-server
(on node0)
% sudo droonga-engine-catalog-generate \
--hosts=node0
% sudo systemctl restart droonga-engine
% sudo systemctl restart droonga-http-server
前回のベンチマークの影響をなくすために、各ベンチマークの実行前にはサービスを再起動することをおすすめします。
これにより、node0は1ノード構成のクラスタとして動作するようになります。
実際にノードが1つだけ認識されていることを確認しましょう:
(on node3)
% curl "http://node0:10042/droonga/system/status"
{
"nodes": {
"node0:10031/droonga": {
"live": true
}
}
}
ベンチマークを実行しましょう。
(on node3)
% drnbench-request-response \
--step=2 \
--start-n-clients=0 \
--end-n-clients=20 \
--duration=30 \
--interval=10 \
--request-patterns-file=$PWD/patterns.txt \
--default-hosts=node0 \
--default-port=10042 \
--output-path=$PWD/droonga-result-1node.csv
デフォルトのポートが10041(GroongaのHTTPサーバのポート)から10042(Droongaのポート)に変わっていることに注意して下さい。
結果の保存先のパスも変わっています。
ベンチマークの実行中、node0のシステムの状態をtopコマンドなどで監視しておきましょう。
これはボトルネックの分析に役立ちます。
また、結果が正しいかどうかを確かめるために、実際のキャッシュヒット率を確認しておきましょう:
% curl "http://node0:10042/statistics/cache"
{
"hitRatio": 49.830717830807124,
"nHits": 66968,
"nGets": 134391
}
"hitRatio"の値に注目してください。HTTPサーバにおける実際のキャッシュヒット率は、上記のようにパーセンテージで示されます(49.830717830807124という値はそのまま49.830717830807124%ということです)。
もし値が期待されるキャッシュヒット率と大きく異なっている場合、何かがおかしいです。
2ノード構成でのDroongaのベンチマーク
ベンチマークの前に、2番目のノードをクラスタに参加させます。
(on node0, node1)
% sudo droonga-engine-catalog-generate \
--hosts=node0,node1
% sudo systemctl restart droonga-engine
% sudo systemctl restart droonga-http-server
これにより、node0とnode1は2ノード構成のDroongaクラスタとして動作するようになります。
実際にノードが2つ認識されていることを確認しましょう:
(on node3)
% curl "http://node0:10042/droonga/system/status"
{
"nodes": {
"node0:10031/droonga": {
"live": true
},
"node1:10031/droonga": {
"live": true
}
}
}
ベンチマークを実行しましょう。
(on node3)
% drnbench-request-response \
--step=2 \
--start-n-clients=0 \
--end-n-clients=20 \
--duration=30 \
--interval=10 \
--request-patterns-file=$PWD/patterns.txt \
--default-hosts=node0,node1 \
--default-port=10042 \
--output-path=$PWD/droonga-result-2nodes.csv
--default-hosts で2つのホストを指定していることに注意して下さい。
今の所、droonga-http-serverはシングルプロセスのため、すべてのリクエストを1つだけのホストに送るとdroonga-http-serverがボトルネックとなってしまいます。
また、droonga-http-serverとdroonga-engineがCPU資源を奪い合うことにもなります。
Droongaクラスタの性能を有効に測定するためには、各ノードのCPU使用率を平滑化する必要があります。
もちろん、実際のプロダクション環境ではこのようなリクエストの分配はロードバランサーによって行われるべきですが、ベンチマークのためだけにロードバランサーを設定するのは煩雑です。
--default-hostsオプションにカンマ区切りで複数のホスト名を指定することで、その代替とすることができます。
また、結果の保存先のパスも変えています。
ベンチマークの実行中、両方のノードのシステムの状態を監視することを忘れないでください。 もし片方のノードだけに負荷がかかっていてもう片方がアイドル状態なのであれば、両者が1つのクラスタとして働いていないなどのように、何か異常が起こっていると分かります。 すべてのノードの実際のキャッシュヒット率も忘れずに確認しておきましょう。
3ノード構成でのDroongaのベンチマーク
ベンチマークの前に、最後のノードをクラスタに参加させましょう。
(on node0, node1)
% sudo droonga-engine-catalog-generate \
--hosts=node0,node1,node2
% sudo systemctl restart droonga-engine
% sudo systemctl restart droonga-http-server
これで、node0, node1, node2のすべてのノードが3ノード構成のクラスタとして動作するようになります。
実際にノードが3つ認識されていることを確認しましょう:
(on node3)
% curl "http://node0:10042/droonga/system/status"
{
"nodes": {
"node0:10031/droonga": {
"live": true
},
"node1:10031/droonga": {
"live": true
},
"node2:10031/droonga": {
"live": true
}
}
}
ベンチマークを実行しましょう。
(on node3)
% drnbench-request-response \
--step=2 \
--start-n-clients=0 \
--end-n-clients=20 \
--duration=30 \
--interval=10 \
--request-patterns-file=$PWD/patterns.txt \
--default-hosts=node0,node1,node2 \
--default-port=10042 \
--output-path=$PWD/droonga-result-3nodes.csv
また--default-hostsと--output-pathの指定も変えていることに注意して下さい。
各ノードのシステムの状態の監視と、実際のキャッシュヒット率の確認も忘れてはいけません。
結果を分析する
これで、手元に4つの結果が集まりました:
groonga-result.csvdroonga-result-1node.csvdroonga-result-2nodes.csvdroonga-result-3nodes.csv
先に述べた通り、これらを使って傾向を分析することができます。
例えば、これらの結果は以下のようにグラフ化できます:
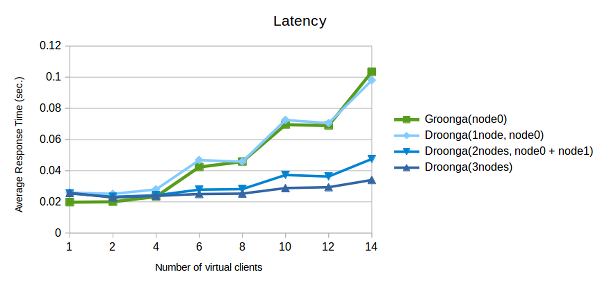
このレイテンシーのグラフは以下のように読み取れます:
- Droongaのレイテンシーの下限はGroongaのそれよりも大きい。 Droongaにはオーバーヘッドがある。
- 複数ノードのDroongaのレイテンシーはGroongaに比べると緩やかに増大している。 Droongaは余計な待ち時間無しでより多くのリクエストを同時に処理できる。
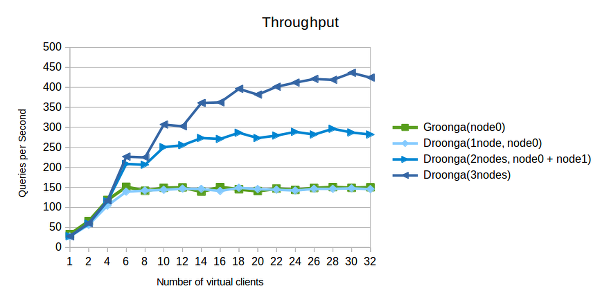
このスループットのグラフは以下のように読み取れます:
- GroongaのグラフとDroongaの単一ノード時のグラフは似通っている。 GroongaとDroongaの間での性能の劣化はごくわずかである。
- Droongaのスループット性能はノード数によって増大する。
(注意: 性能測定の結果は様々な要因によって変動します。 これはあくまで特定のバージョン、特定の環境での結果の例です。)
まとめ
このチュートリアルでは、比較対照としてのGroongaサーバと、Droongaクラスタを用意しました。 また、リクエストパターンを用意する手順、システムの性能の測定方法、結果の分析方法なども学びました。